SSC Meta-Data System
.![]() -
- ![]() -
- ![]() -
- ![]()
SSC Meta-Data System |
. |
Our initial objective is to be able to associate meaning information with the data values stored in the underlying application (the Host application). We need both information about the meaning of the actual values stored, and also about the variables (fields) to which these values belong, the underlying concepts which the data values are about. To do this we define two fundamental entities, a Scale and a Code.
Figure 2: CMD Entities
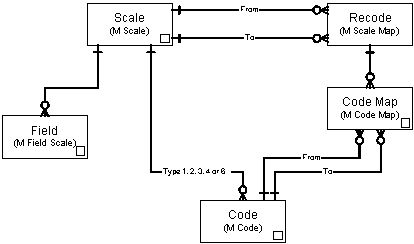 A Scale is an entity for recording
information about a particular concept, and a Code is a value within a concept. A Scale can be thought of as a
generalisation of the relational concept of a Domain, and a Code is a value within a domain.
A Scale is an entity for recording
information about a particular concept, and a Code is a value within a concept. A Scale can be thought of as a
generalisation of the relational concept of a Domain, and a Code is a value within a domain.
Figure 2 shows the main entities of the system and the links between them (the actual table names used are shown in parentheses). The detailed contents of the tables used to store information about these entities are listed in section 5. Here we provide a quick overview of the contents in order to give a general context for the more detailed descriptions which follow.
Every Field (or Variable, stored or derived) is linked to a Scale, and different variables can share the same Scale. A Scale has as attributes a Name, a Label, a Description, a Type and a Status. The type can be Coded (integer1 or text2), Numeric (integer3 or floating4), Date5, Free Text6 or Logical7. (The suffices correspond to the numeric codes used within the system to identify the different Scale types.) The status is used to identify (and protect) the scales used by the system itself. A Field can have its own Label and Description, with those for the Scale acting as defaults.
A Code record has as attributes the Scale to which it belongs, the Code itself (numeric or text), a Label and Description, and a Status. If the status is not null then the code is a Special Value for the scale. For coded scales all possible values must have code records. For other scales (except dates or logicals) code records can be used to declare special values for the scale. One special value for a scale can be set to be equivalent to Null.
Note that this is different from the simplistic approach achieved by normalising tables which include labels as well as codes. That leads to a table of codes and labels for each variable but fails to recognise any generalising structure within the problem.
A Recode is a mapping between two coded scales. The components of a recode are ordered pairs of from and to codes (the Code Map elements). This provides for hierarchical relationships between scales, that is, one scale can be mapped to another where the codes of the second scale correspond to groups of codes from the first. Examples are the mapping from detailed to coarse exposure categories, or from Districts to Regions. These mappings convert values declared as codes from one scale to another, and so can be defined for any pair of scales which can have entries in the Code table M Code. They can convert between numeric and text scales. Structures for recoding ranges of numeric scales and for setting range limits and output formatting are planned but not implemented at the time of writing.
These structures allow us to record information about the concepts which underlie the information collected in the data tables for the application, and to record hierarchical relationships between these concepts. As an aside, they also provide a general facility for the application designer to store named lists of values and translation tables between them.
The structures described above provide for the storage of information about the variables and codes which form the content of the host application. Using the link from the field name it is easy to write SQL queries which extract required information about a variable or about one of its codes, simply by selecting on the field name.
A (simplified) example might be:
Select [Data].[Diagnosis], [M Code].[Code Label] from [Data], [M Code] Where [M Code].[Scale Name] = "Diagnosis" and [M Code].[Code] = [Data].[Diagnosis]
However, this is where the problem lies for any attempt to implement generic facilities in a strict relational sense. A field (or attribute) name (such as [Diagnosis]) is not data. When we write a field name in an SQL statement we are actually referring to the data values stored in the records (tuples). When we select information from the meta-data we need to use the field name (or its linked scale) as a data value (the string "Diagnosis") in a Where clause. While this is clearly trivial to do in any particular case, there is no formal link between the field name ([Diagnosis]) and the string ("Diagnosis") used in the example. This makes it difficult to automate process which operate over arbitrary columns, and makes code which references columns explicitly difficult to maintain.
Note that in a fully object-based system this would probably not be a problem, since the name of the parent attribute of a data value would (probably) be available as a property of the object containing the value. We could then implement methods on the data objects which returned appropriate attributes of the linked scale for the value. While much of MS Access is object-based, data values themselves are not objects (though table columns are in some contexts, but not in SQL).
We have not been able to overcome this problem. So we live with it, but attempt to simplify and manage it. Our approach has been to write a set of functions which implement the methods we would like to have, and which simplify the writing of statements to access the meta-data. The functions are discussed in more detail below, but, for example, the SQL statement above can be simplified to:
Select [Diagnosis], M_Label("Diagnosis", [Diagnosis]) from [Data]
While the principle reason for having the meta-data is to inform use and analysis of the data in the application, since we do have it we can make use of it in other ways to improve the operation and management of the database. Two examples are presented.
In MS Access, Forms provide the main medium for the entry of data. These are build up from various elements, including Controls to hold data. Both Forms and Controls are objects, with properties and methods. The programming behind Forms and Controls is event-based, with routines being invoked by the system when various events occur. The event model is rich, and provides a powerful environment for the programmer to control the operations which take place within the form.
Figure 3: Combo Box Codes
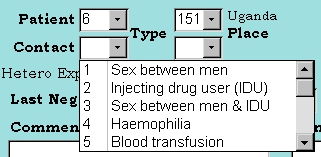 Where a control
is linked to a coded Scale we may wish to constrain input into
the control to the values in the Scale. Access provides a control
(the Combo box) which has the functionality of constraining entry
to values in a list, and we have built a facility to set the list
of values dynamically. A special flag is placed into the
definition of the combo control. When the form is opened (when
the Open event occurs)
a call is made to routine M_List_Row_Source.
This scans all the Control objects within the Form object,
looking for combo controls with the special flag set. When it
finds one it traces from the control name to the linked scale,
and sets the source list for the control to the set of values
allowed for the scale. This does not require any explicit
constants, since it is based entirely on properties of the
objects and data in the meta-data tables. And if the meta-data is
changed the revised codes are immediately enforced in the data
entry forms.
Where a control
is linked to a coded Scale we may wish to constrain input into
the control to the values in the Scale. Access provides a control
(the Combo box) which has the functionality of constraining entry
to values in a list, and we have built a facility to set the list
of values dynamically. A special flag is placed into the
definition of the combo control. When the form is opened (when
the Open event occurs)
a call is made to routine M_List_Row_Source.
This scans all the Control objects within the Form object,
looking for combo controls with the special flag set. When it
finds one it traces from the control name to the linked scale,
and sets the source list for the control to the set of values
allowed for the scale. This does not require any explicit
constants, since it is based entirely on properties of the
objects and data in the meta-data tables. And if the meta-data is
changed the revised codes are immediately enforced in the data
entry forms.
Figure 4: Help from the CMD system
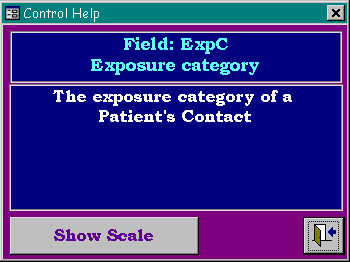 A generic Help system is
provided, linked to the meta-data. At any point in the system a
special key sequence (Ctrl-F1) can be used. This invokes routine M_Control_Help. This
routine obtains the name of the control at which the user was
working, and from this links through to the meta-data to obtain a
suitable description for the control. This is displayed in a
pop-up form, which includes a link to the definition of the scale
in case the user wishes to see more details.
A generic Help system is
provided, linked to the meta-data. At any point in the system a
special key sequence (Ctrl-F1) can be used. This invokes routine M_Control_Help. This
routine obtains the name of the control at which the user was
working, and from this links through to the meta-data to obtain a
suitable description for the control. This is displayed in a
pop-up form, which includes a link to the definition of the scale
in case the user wishes to see more details.
The main advantage of this facility is that the information shown by the help system is data in the meta-data tables, which means that it is the database administrator who is responsible for it, not the programmer. Thus the help information can be updated in the light of user reaction or difficulties.
Page last updated 18 June, 2003.