
This paper was presented by Andrew Westlake at the Compstat conference in Utrecht in 1998
Keywords. Multi-way table, Manipulation, Dissemination, Automation
This paper reviews the technologies required for the production and publication of large volumes of statistical information, such as produced by National Statistical Offices (NSOs). We review both academic and commercial developments, and present these in the context of an analysis of the tools and structures needed.
Our ultimate objective is improvement in the accessibility and use of data from large or continuous surveys and inquiries. These are characterised as having a significant volume of data processing and output, often with complex processing to produce representative and comparable figures, but not great depth of analysis. Production will generally be in the form of large amounts of classified summary data, and analysis will be in the form of comment on trends perceived in headline summary figures. Some clients will extract small volumes of data of specific interest, while others will want to perform more detailed analysis.
We are looking for an approach to be applied after initial data entry and cleaning, which provides support for:
We conclude that useful progress has been made, but much remains to be done.
The data structure required for storing summary information is a multi-way table, a hypercube with multiple dimensions, and cells containing multiple values. Each dimension is a classification structure, with consolidation from detail to broad groups through various levels of aggregation in a hierarchical tree (more strictly, an acyclic graph). Each cell of the table contains multiple measures, the same in all cells, which can be counts, sums, means, or other expressions. Fig 1 shows these components in a hypothetical medical example, with classifications by time, location and disease. Note that the structure for time is not a simple hierarchy, because weeks and months do not map into each other.
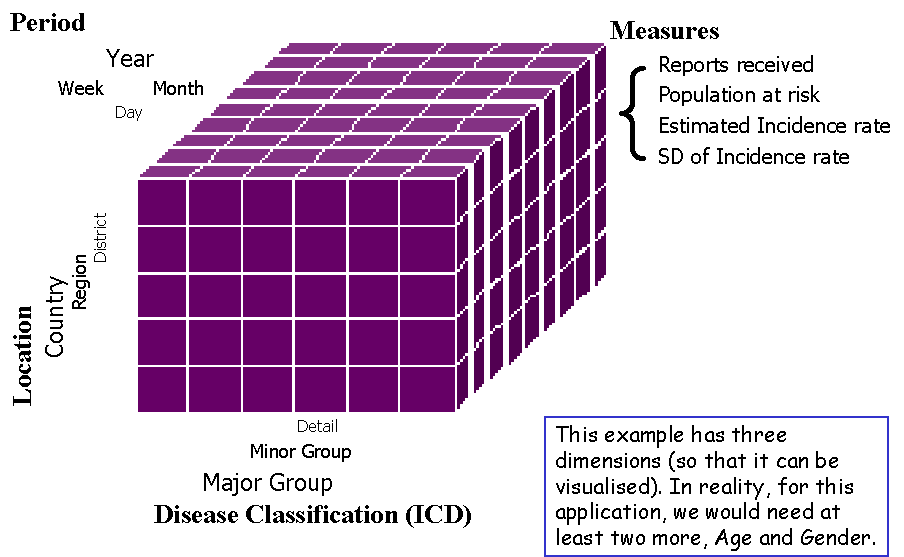
Fig 1. A Hypercube with Dimensions and Measures
Formal work on this structure has been carried out in the statistical database field from at least the early 1980’s, and is found particularly in the SSDBM conference proceedings, with work by Rafanelli and Shoshani on the Storm model being central. An alternative, more commercial, thread can be traced from work by Codd (who coined the term Olap – OnLine Analytical Programming) and has resulted in various tools, from database vendors (Oracle , Ingress, MS SQL Server ) and specialist firms, generally referring to Data Warehousing, or Data Cubes . This work is based on more traditional computer science views of databases and does not give much attention to the specific requirements of statistics, such as validity rules or contextual meta-data. Some special statistical products also exist, such as Beyond 20/20 , SuperCross and PC-Axis.
From formal analysis of the nature and properties of the structure we can derive precise rules for specifying a table, plus consequential properties and behaviour. For example, clear rules are needed for identifying the underlying population elements that are described by a table (for ensuring that classification categories are exclusive and exhaustive) and for identifying different types of summary measure. This then leads to rules for computing aggregations of measures (for margins and consolidation) and for deriving additional measures (such as rates).
Automation is possible with a formal model of structure and functionality. An object model (consisting of structures, properties and methods) can be defined, and implemented as a set of programming objects with a suitable API (programming interface). This then provides the basis for application developers to implement specific tasks, or for the development of general-purpose packages. Using such tools it is possible to construct statistical production systems where the processes to be applied to statistical data are parameterised, using suitable meta-data.
Microsoft have proposed a standard API for use with OLAP products (an attempt at a broader standard through the OLAP Council did not succeed). The new Met-aware project, funded by Eurostat , is proposing to produce a production system linked to data warehouse products and building on the meta-data repository system Bridge, which was produced by the earlier IMIM project. A further project (Meta-Net) has been proposed, to establish a network of organisations involved in statistical meta-data, with a view to establishing coherence between various standardisation efforts and disseminating information about these efforts.
Fig 2. Processes in Statistical Production
Fig 2 shows the various components in a possible statistical processing system, plus the major flows of data. On the right is the database, holding all the data. This includes the source registers for sampling (the sampling frames) and the returned records from the surveys or inquiries. It also includes the various parameters that drive the processing of the data (such as the sampling rates within strata).
There should also be explicit, structured storage of the various aggregated results of the inquiries, in the form of multi-way tables. This is logically part of the same database, but may be physically separate.
The boxes on the left of the diagram show processes applied to the data in the database. Those in the lower box are the ones currently implemented in most statistical processing systems. Some processes covered by the headings in the upper box are currently in place, but most of these are treated as tasks to be done manually outside the main statistical data processing system. We suggest that these should be implemented in a more formalised and standardised way, taking data from the database and returning derived values there.
In a traditional system, grossing and aggregation are tightly coupled to the specific reports needed for particular publications. The approach we are proposing here is to do as little aggregation as possible initially (i.e. to retain as much detail in classifications as is possible), thus retaining the option for much more flexible aggregation, whether for a number of different publications, or for analysis on demand. In the database literature there is considerable discussion about the physical aspects of storing aggregates, in particular about the efficiency trade-off between the space used to store more heavily aggregated data and the speed of retrieval from having the aggregations pre-calculated. However, logically, all aggregations derivable from the detailed classifications are available.
From a mathematical perspective, most of the processes applied to aggregate data are straightforward. The complex processes are the estimation of statistical precision (where complex sample designs are involved) and disclosure control (the avoidance of the disclosure of information about individual respondents).
Aggregation is simple (given knowledge of the types of measure involved), and most analysis in this context is little more than aggregation. Almost all aggregations are ultimately based on summation of more or less complex functions of the values from the underlying micro-data records (note that counts are sums of 0/1 indicator variables). More complex measures are obtained by applying formulae to sets of sums. So means (sum / count), percentages (restricted count / overall count) and ratios (sum1 / sum2) are all based on two sums, and standard deviations are based on three (sum of squares, sum and count). This refers back to the old statistical idea of ‘sufficient statistics’, the aggregates that need to be carried forward when summarising data, in order to be able to derive the appropriate statistical measures.
So the trick in managing the aggregation process for measures is to ensure that all the component (sum) measures are explicitly available. Then higher levels of summarisation can be derived from the more detailed aggregate tables, without having to return to the underlying micro-data records.
Of course, there are some statistical measures that are not based on sums. Some still support aggregation (such as minimum and maximum – and hence range), but many can only be derived from the micro-data – these are generally measures based on non-linear combinations of the micro-data values.
Some special dimensions, particularly time, also require care. For example, on a time dimension it is essential to differentiate between measures that represent aggregations over time (such as revenue) and those that represent cross-sectional observations (such as number of employees). Lenz and Shoshani have done important work on this topic.
Grossing (the production of estimates for the whole population instead of just the sample) is done by applying factors representing the proportion of the population covered by the sample (either known or separately estimated factors, often ratio-based factors). More general adjustments are applied where the population sampled differs from the population for which results are to be reported. The most obvious example is in the National Accounts, where adjustment is made for known or estimated underreporting and concealment. Standardisation (such as adjustment to constant prices or the removal of seasonal effects) is similar, except that the data being adjusted may contribute to the factors to be applied. In general, all these operations involve the multiplication of measures in one multi-way table by factors from some other multi-way table, perhaps formed by aggregating the first.
Traditional statistical publishing has concentrated on the production of a number of predefined tables, which are then committed to paper and fixed. However, developments in the Olap and data warehouse field have emphasised the dynamic nature of publication, with the aggregate data viewed as a resource to be explored by the user. The ubiquity of the Internet has reinforced this approach.
So we should view a multi-way table as the basis of a dynamic facility, through which a user can extract information of interest. This is similar to the idea of a view in a relational database. To support these dynamic views, various operations are required.
Selection, as in an RDBMS, is the operation to extract subsets of classifications and measures. There is also a need to reduce or increase detail in a classification, for example, moving from detailed to broad groups on a dimension, or showing the next level of detail for a particular group. These operations are called roll-up and drill-down in Olap terminology. Roll-up includes extraction of margins, the complete removal of some dimensions. A user may want to define new groupings within classifications, as combinations of existing groups.
The derivation of additional measures and classifications requires manipulation functionality, and also rules about the validity of the operation and the nature of any derived measure. With a production system we can assume that the derivation specifications are appropriate, but this is not reasonable for a system open to use by uncontrolled users. So we need to recognise the different types of measure in cells and the different types of operation between measures. It is then possible to warn a user can be warned if an operation could be invalid. Note that it is not in general possible to make absolute rules, since the user may have more information about the data than the system has.
As well as within cells, measure derivations can operate within and across classifications, and between tables. It seems likely that a general approach to this, based on operations between tables, can encompass all these cases. We need to define how the measures and dimensions of related but different tables can be combined, using repetition and distribution. Then the final step uses operations between measures within cells, as before. This will need rules to determine when tables are mutually conformant, which will draw heavily on explicit representation of the underlying population objects for the tables, and of the selection rules for the population and the measures.
An important aspect of this approach to summary information is the separation of the internal, logical structure of the data from the external layout required for presentation. Additional functionality is required to support presentation, whether on screen, on paper, or in some other form. We need to map from logical structure to presentation layout, through the specification of rows, columns and pages, and to combine separate tables (in more ways than are needed for manipulation). When used in a browsing context the functionality should be dynamic, allowing the user to explore the data, as described previously. The ‘Pivot Table’ component of MS Office 2000 provides a good initial model for this, and Beyond 20/20 is more statistically oriented, though a little less flexible.
For dissemination it must be possible to generate different types of output, and with different packaging. While the full detail tables will be retained for internal use, exported tables will generally have less detail, so views will be turned into real tables. It is essential that disclosure control can be applied to exported tables, and to all other released material. Statistical reliability can be addressed by including appropriate measures in the tables.
For publication on paper, MS Office (or similar) products provide a good environment for generating reports and analyses (including automation options). Publication of static pages on the web is essentially the same problem but with different output formats and better navigation options, and, again, recent office products are addressing this issue. However, the web will also need dynamic versions, for exploration. Initial examples are provided by the ONS Statbase service, and the Beyond 20/20 web server. The Olap products generally address this as well, and a number of NSOs (such as The Netherlands and Hungary) are building systems using data warehouse products. Web access (or any other form of on-line access) has the important advantage of timeliness over any static dissemination method.
Users who need machine readable output should be able to export or download information. Spreadsheets provide a suitable form for simple cases, but full multi-way tables will be needed for in-depth analysis, which implies the availability of manipulation or browsing software for the user. Dissemination on CD, while less timely, addresses problems of scale and direct web access, but can simply reproduce the web content, providing static, dynamic and extract facilities through a browser.
Page last updated 23 September 2005.